1. Venus vs Other Instruction Set Architectures
Venus Speedups: 2.3× (FFT), >2× (Matrix), Linear Scaling (Multi - Lane)
Venus vs Others: ~1× (General - Purpose), 1.8×/0.7× (DSP), >1.5× (All 5G + AI Tasks)
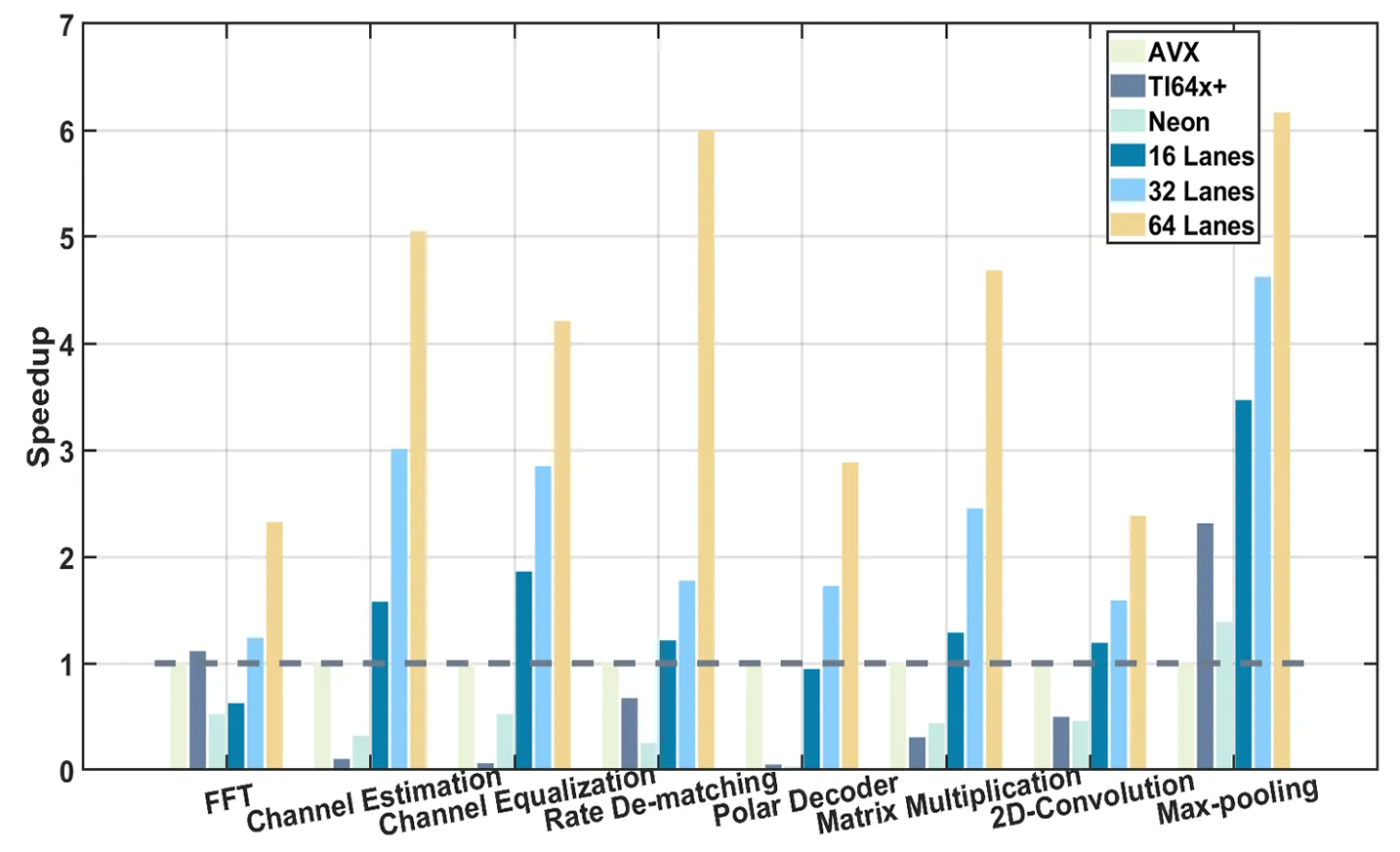
· Test Design
(1)Task Selection
○ 5 tasks from 5G physical layer (FFT, Channel Estimation, Channel Equalization, Rate De - matching, Polar Decoder) ;
○ 3 AI tasks (Matrix Multiplication, 2D - Convolution, Max - pooling).
(2)Parameter Configuration
○ For 5G tasks: 20 MHz bandwidth, 96 RBs, MCS = 28; FFT uses radix - 2 decimation - in - time; channel estimation/equalization adopts least - squared method; polar decoding applies belief propagation.
○ For AI tasks: matrix multiplication (64×32 & 32×256 matrices); 2D convolution kernel (16×16); max - pooling window (16×16).
(3)Comparison Architectures
Intel AVX (x86 vector extensions),
Arm Neon (ARM vector instructions),
TI C64x + DSP (dedicated signal processor),
Venus tiles (16/32/64 lanes).
(4)Optimization Strategies
○ Intel AVX/Arm Neon: built - in intrinsics + compiler + digital library;
○ TI DSP: compiler - only;
○ Venus: customized vector extensions (complex shuffle units, extended vector instructions).
· 📈 Performance Results
(1)Single - lane Competitiveness (16 - lane)
○ FFT: Venus (radix - 2 optimization + data rearrangement) → 2.3× speedup vs TI C64x + DSP.
○ Matrix Multiplication: customized vector parallelism → >2× speedup vs Arm Neon (shows DSA advantage over general - purpose architectures).
(2)Multi - lane Scalability (32/64 - lane)
Linear speedup growth with lanes (matches Amdahl's law).
E.g., Polar Decoder: 5.7× (64 - lane vs 16 - lane); 2D - Convolution: >6 (64 - lane vs Intel AVX) → verifies hardware parallelism gain for hybrid loads.
(3)Task Adaptation Differences
○ General - purpose (AVX/Neon): ~1× speedup in “irregular parallel” tasks (Polar Decoder, limited by software scheduling).
○ Dedicated DSP (TI C64x +): 1.8× in 5G (Channel Equalization), 0.7× in AI (Max - pooling, architecture mismatch).
○ Venus (DSA - based): >1.5× speedup in all “5G + AI” tasks → more balanced adaptation.
2. Venus vs Other Hardware
Venusian Performance: 51.57× Faster Than Arm Baseline; Intel CPU/GPU Are 3.61×/292.61× Slower
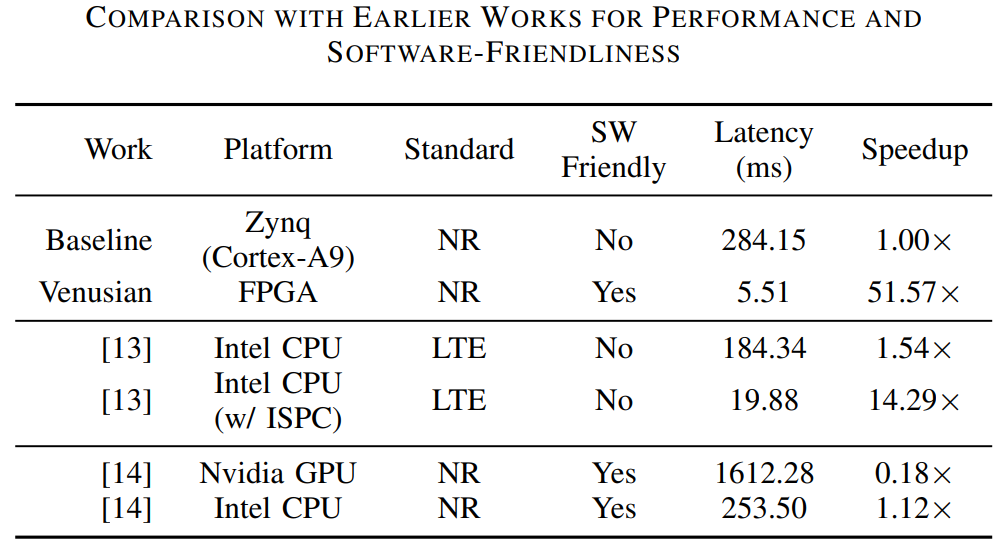
[13] Y. Shen, F. Yuan, S. Cao, Z. Jiang, and S. Zhou, “Parallel computing for energy-efficient baseband processing in O-RAN: Synchronization and OFDMimplementation based on SPMD,” in Proc. IEEE Glob. Commun. Conf. (GLOBECOM), pp. 2736–2741, IEEE, 2023.
[14] J. Hoydis, S. Cammerer, F. A. Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, “Sionna: An open-source library for next-generation physical layer research,” arXiv preprint arXiv:2203.11854, 2022.
· Comparison Objects
Baseline (Zynq (Cortex - A9) ),
[13] (Intel CPU, Intel CPU (w/ ISPC) ),
[14] (Nvidia GPU, Intel CPU ), and Venusian (FPGA).
· Test Content
Compare link - level performance and software - friendliness. Except Venusian, a BCH decoding baseline runs on Arm CPU (C - implemented).
[13] uses SPMD paradigm with Intel CPUs + ISPC compiler;
[14]'s Sionna leverages TensorFlow for GPU - based simulation.
· 📈 Performance
○ Vs. Arm baseline, Venusian achieves 51.57× speedup, reducing programming effort. Latency improvement comes from its hardware SIMD capability.
○ Intel CPU has similar latency to Arm baseline without ISPC. After optimization, it's still 3.61× slower than Venusian (with multi - core & SIMD).
○ Sionna offers rich visualization but low efficiency. On GPU, it's up to 292.61× slower than Venusian, likely due to CPU - GPU data transfer overhead.
3. UVP vs Ara
UVP Performance Blows Away Ara: Far Fewer Cycles in Matmul/FFT, Up to 3.0× Speedup
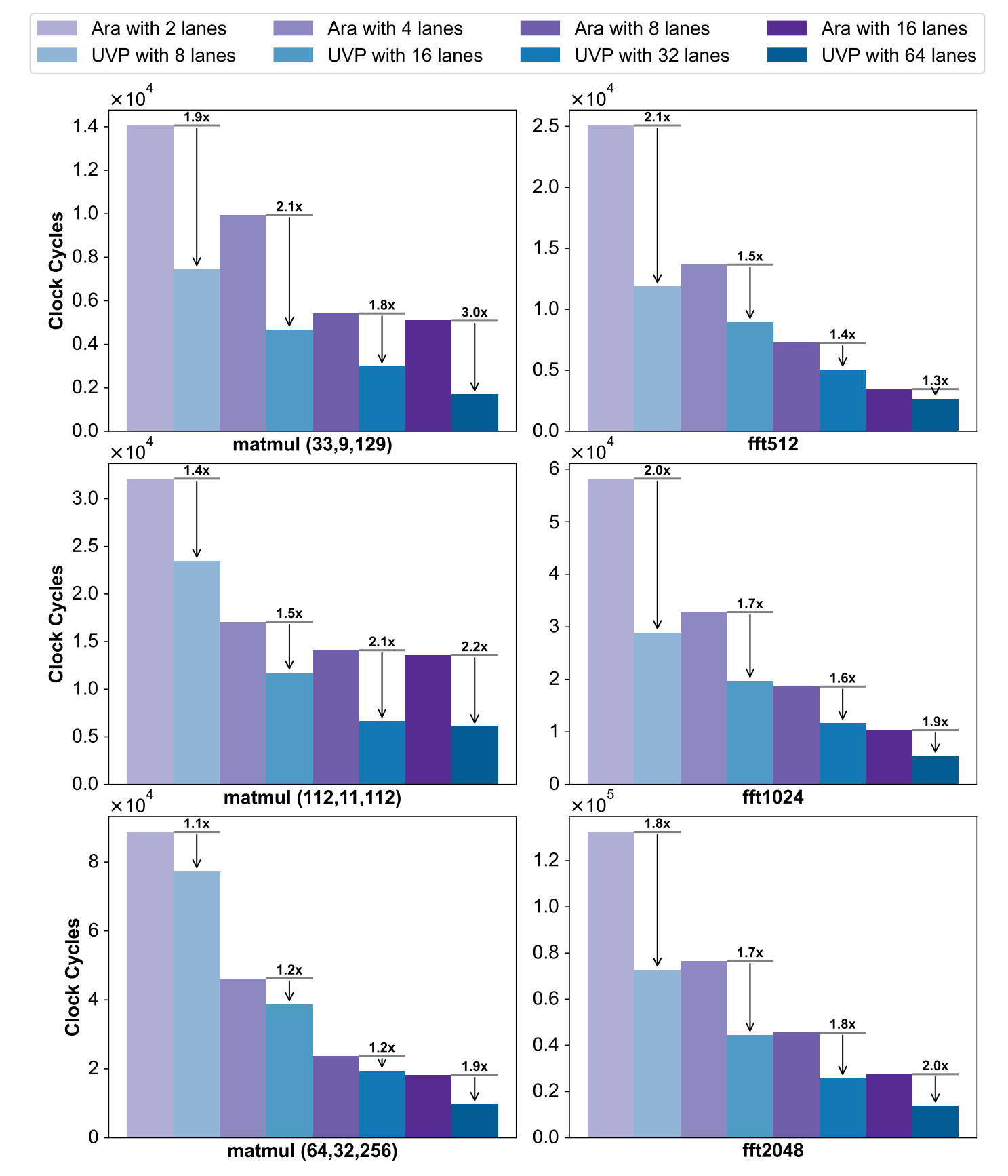
· Objective
Verify UVP's clock cycle optimization and performance acceleration vs. Ara architecture, under different lane configs and computing kernels (matmul, FFT).
· Test Content
○ Tasks & Configs:Select matmul (e.g., (33,9,129)) and FFT (e.g., 512/1024 points) tasks. Compare Ara (2/4/8/16 lanes) and UVP (8/16/32/64 lanes, ensuring fair execution unit comparison: L - lane Ara → 4L - lane UVP).
○ Metrics:Use clock cycles to evaluate efficiency; speedup reflects UVP's performance gain over Ara.
· 📈 Performance
(1)Clock Cycle Optimization
○ In matmul (33,9,129), UVP (8 lanes) has far fewer cycles than Ara (2 lanes); more UVP lanes (16/32/64) → fewer cycles.
○ Same for FFT (fft512): UVP cycles < Ara for all configs.
(2)Speedup
○ Matmul: 1.1× - 3.0× (more significant when matrix dims ≠ powers of two, ≥1.4×).
○ FFT: 1.2× - 1.3×. If butterfly input exceeds Ara's vector register capacity, UVP benefits more from flexible RGs and larger VRFs.
4、PBCH Decoding Latency Breakdown
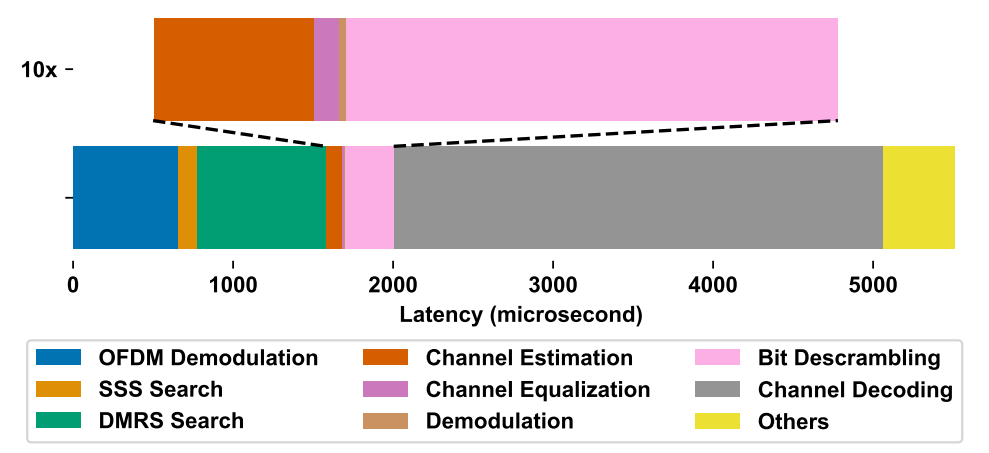
· Test Scenario
Analyze PBCH decoding latency at 50 MHz with Lane32Reg1024 config (including DMRS).
· Task Decomposition
Break down PBCH decoding into 9 sub - procedures: OFDM Demodulation, Channel Estimation, Bit Descrambling, SSS Search, Channel Equalization, DMRS Search, Demodulation, Channel Decoding, and Others—covering the full link from signal preprocessing to data decoding.
· 📈 Core Latency Characteristics
○ Most Time - Consuming:Channel Decoding (Polar code belief propagation), latency depends on signal quality (worse signal → more iterations → higher latency).
○ Next Critical:OFDM Demodulation (3 FFTs + time - frequency conversions) and DMRS Search (candidate sequence correlation + pseudo - random generation via complex permutations/summations).
○ Low - Impact:Bit Descrambling, SSS Search, etc., have low complexity and minimal impact on total latency.